Java 中九種 Map 的遍歷方式
來(lái)源:
奇酷教育 發(fā)表于:
2022-11-17 09:26:37
Java 中九種 Map 的遍歷方式
日常工作中 Map 絕對(duì)是我們 Java 程序員高頻使用的一種數(shù)據(jù)結(jié)構(gòu),從最早的Iterator,到j(luò)ava5支持的foreach,再到j(luò)ava8 Lambda,你經(jīng)常使用的是哪一種?
通過 entrySet 來(lái)遍歷
1、通過 for 和 map.entrySet() 來(lái)遍歷
第一種方式是采用 for 和 Map.Entry 的形式來(lái)遍歷,通過遍歷 map.entrySet() 獲取每個(gè) entry 的 key 和 value,代碼如下。這種方式一般也是阿粉使用的比較多的一種方式,沒有什么花里胡哨的用法,就是很樸素的獲取 map 的 key 和 value。
public static void testMap1(Map<Integer, Integer> map) {
long sum = 0;
for (Map.Entry<Integer, Integer> entry : map.entrySet()) {
sum += entry.getKey() + entry.getValue();
}
System.out.println(sum);
}
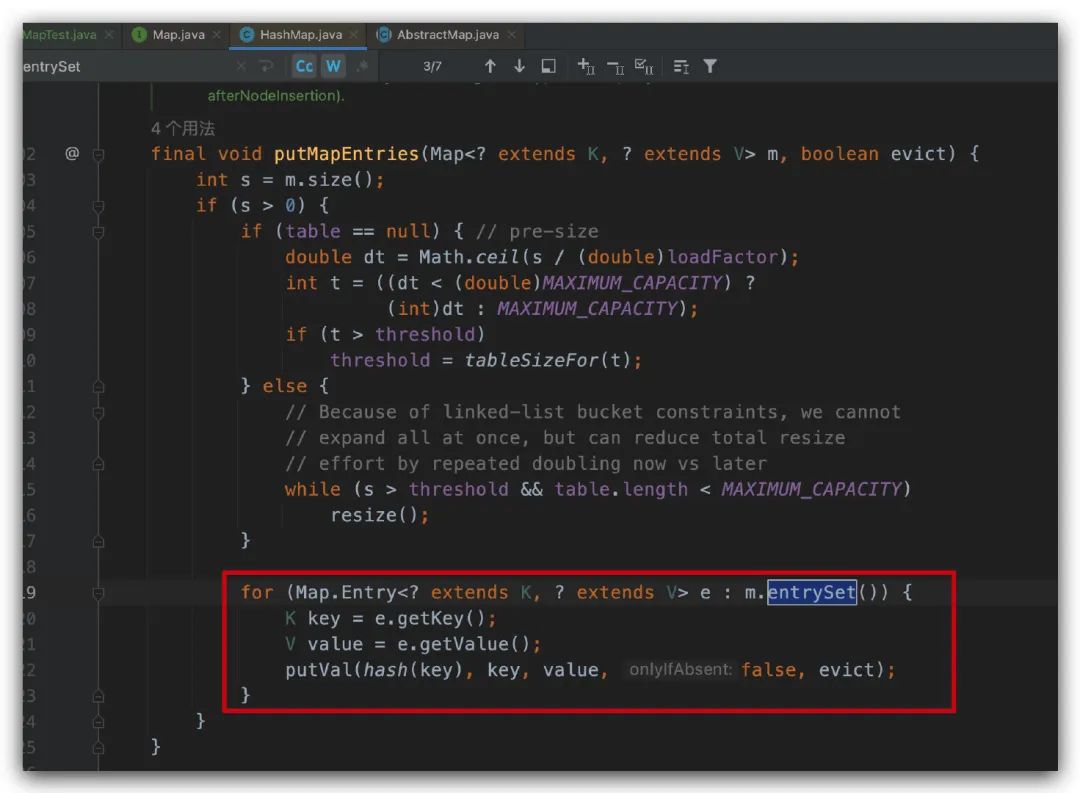
看過 HashMap 源碼的同學(xué)應(yīng)該會(huì)發(fā)現(xiàn),這個(gè)遍歷方式在源碼中也有使用,如下圖所示,
putMapEntries 方法在我們調(diào)用 putAll 方法的時(shí)候會(huì)用到。
2、通過 for, Iterator 和 map.entrySet() 來(lái)遍歷
我們第一個(gè)方法是直接通過 for 和 entrySet() 來(lái)遍歷的,這次我們使用 entrySet() 的迭代器來(lái)遍歷,代碼如下。
public static void testMap2(Map<Integer, Integer> map) {
long sum = 0;
for (Iterator<Map.Entry<Integer, Integer>> entries = map.entrySet().iterator(); entries.hasNext(); ) {
Map.Entry<Integer, Integer> entry = entries.next();
sum += entry.getKey() + entry.getValue();
}
System.out.println(sum);
}
3、通過 while,Iterator 和 map.entrySet() 來(lái)遍歷
上面的迭代器是使用 for 來(lái)遍歷,那我們自然可以想到還可以用 while 來(lái)進(jìn)行遍歷,所以代碼如下所示。
public static void testMap3(Map<Integer, Integer> map) {
Iterator<Map.Entry<Integer, Integer>> it = map.entrySet().iterator();
long sum = 0;
while (it.hasNext()) {
Map.Entry<Integer, Integer> entry = it.next();
sum += entry.getKey() + entry.getValue();
}
System.out.println(sum);
}
這種方法跟上面的方法類似,只不過循環(huán)從 for 換成了 while,日常我們?cè)陂_發(fā)的時(shí)候,很多場(chǎng)景都可以將 for 和 while 進(jìn)行替換。2 和 3 都使用迭代器 Iterator,通過迭代器的 next(),方法來(lái)獲取下一個(gè)對(duì)象,依次判斷是否有 next。
通過 keySet 來(lái)遍歷
上面的這三種方式雖然代碼的寫法不同,但是都是通過遍歷 map.entrySet() 來(lái)獲取結(jié)果的,殊途同歸。接下來(lái)我們看另外的一組。
4、通過 for 和 map.keySet() 來(lái)遍歷
前面的遍歷是通過 map.entrySet() 來(lái)遍歷,這里我們通過 map.keySet() 來(lái)遍歷,顧名思義前者是保存 entry 的集合,后者是保存 key 的集合,遍歷的代碼如下,因?yàn)槭?key 的集合,所以如果想要獲取 key 對(duì)應(yīng)的 value 的話,還需要通過 map.get(key) 來(lái)獲取。
public static void testMap4(Map<Integer, Integer> map) {
long sum = 0;
for (Integer key : map.keySet()) {
sum += key + map.get(key);
}
System.out.println(sum);
}
5、通過 for,Iterator 和 map.keySet() 來(lái)遍歷
public static void testMap5(Map<Integer, Integer> map) {
long sum = 0;
for (Iterator<Integer> key = map.keySet().iterator(); key.hasNext(); ) {
Integer k = key.next();
sum += k + map.get(k);
}
System.out.println(sum);
}
6、通過 while,Iterator 和 map.keySet() 來(lái)遍歷
public static void testMap6(Map<Integer, Integer> map) {
Iterator<Integer> it = map.keySet().iterator();
long sum = 0;
while (it.hasNext()) {
Integer key = it.next();
sum += key + map.get(key);
}
System.out.println(sum);
}
我們可以看到這種方式相對(duì)于 map.entrySet() 方式,多了一步 get 的操作,這種場(chǎng)景比較適合我們只需要 key 的場(chǎng)景,如果也需要使用 value 的場(chǎng)景不建議使用 map.keySet() 來(lái)進(jìn)行遍歷,因?yàn)闀?huì)多一步 map.get() 的操作。
Java 8 的遍歷方式
注意下面的幾個(gè)遍歷方法都是是 JDK 1.8 引入的,如果使用的 JDK 版本不是 1.8 以及之后的版本的話,是不支持的。
7、通過 map.forEach() 來(lái)遍歷
JDK 中的 forEach 方法,使用率也挺高的。
public static void testMap7(Map<Integer, Integer> map) {
final long[] sum = {0};
map.forEach((key, value) -> {
sum[0] += key + value;
});
System.out.println(sum[0]);
}
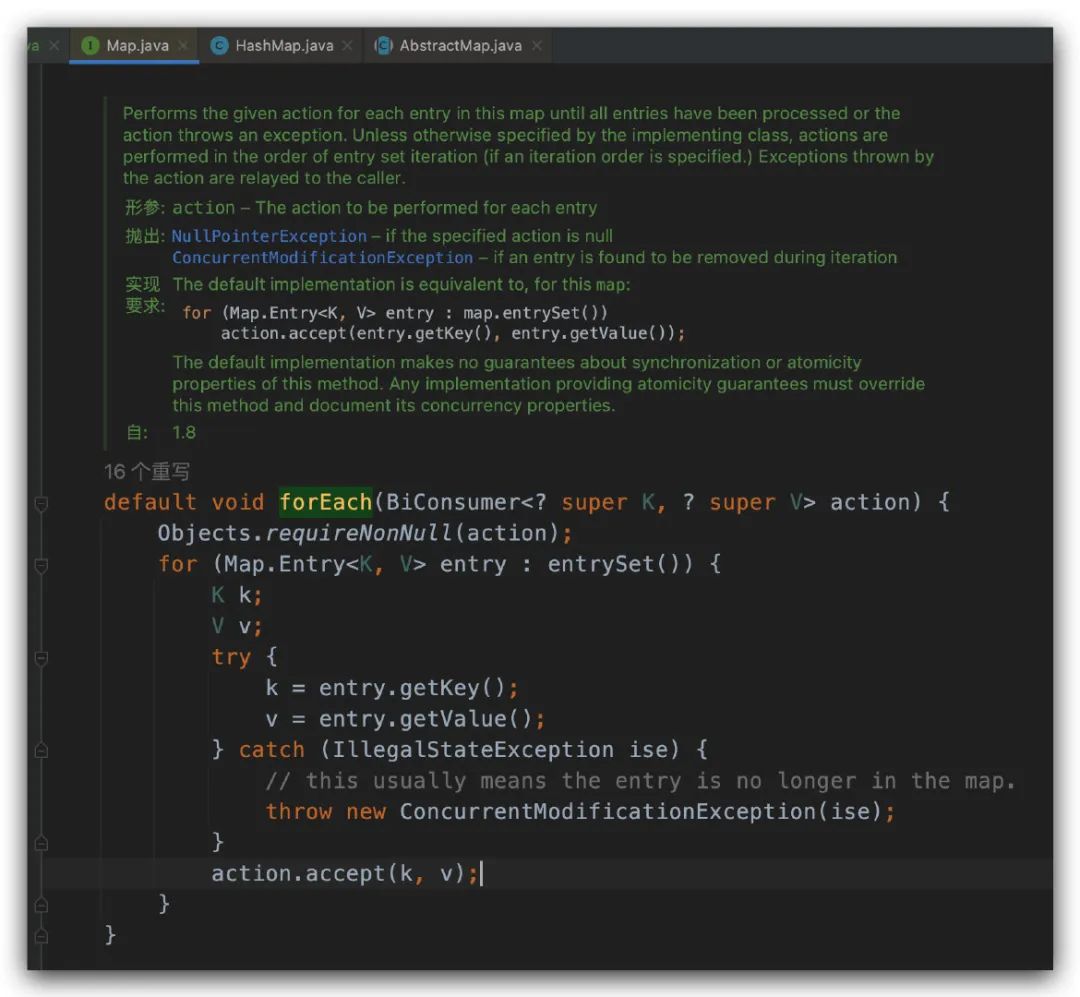
該方法被定義在 java.util.Map#forEach 中,并且是通過 default 關(guān)鍵字來(lái)標(biāo)識(shí)的,如下圖所示。
8、Stream 遍歷
public static void testMap8(Map<Integer, Integer> map) {
long sum = map.entrySet().stream().mapToLong(e -> e.getKey() + e.getValue()).sum();
System.out.println(sum);
}
9、ParallelStream 遍歷
public static void testMap9(Map<Integer, Integer> map) {
long sum = map.entrySet().parallelStream().mapToLong(e -> e.getKey() + e.getValue()).sum();
System.out.println(sum);
}
這兩種遍歷方式都是 JDK 8 的 Stream 遍歷方式,stream 是普通的遍歷,parallelStream 是并行流遍歷,在某些場(chǎng)景會(huì)提升性能,但是也不一定。
測(cè)試代碼
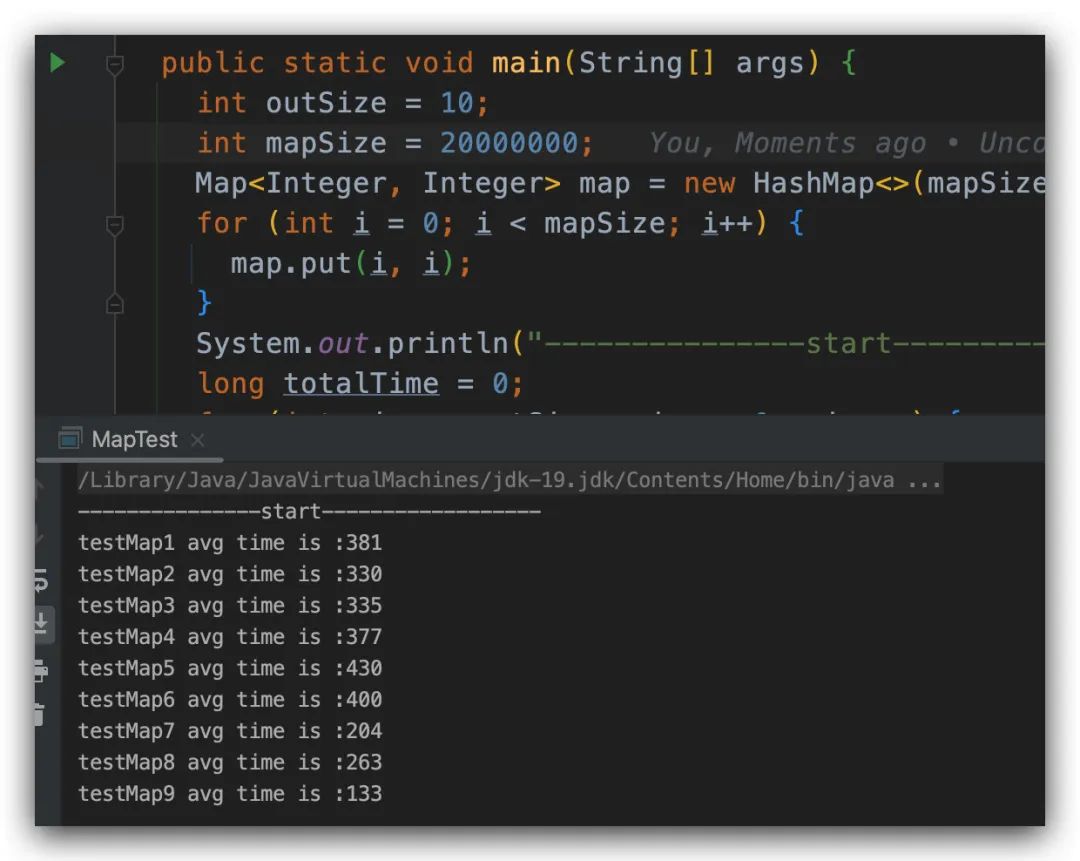
上面的遍歷方式有了,那么我們?cè)谌粘i_發(fā)中到底該使用哪一種呢?每一種的性能是怎么樣的呢?為此阿粉這邊通過下面的代碼,我們來(lái)測(cè)試一下每種方式的執(zhí)行時(shí)間。
public static void main(String[] args) {
int outSize = 1;
int mapSize = 200;
Map<Integer, Integer> map = new HashMap<>(mapSize);
for (int i = 0; i < mapSize; i++) {
map.put(i, i);
}
System.out.println("---------------start------------------");
long totalTime = 0;
for (int size = outSize; size > 0; size--) {
long startTime = System.currentTimeMillis();
testMap1(map);
totalTime += System.currentTimeMillis() - startTime;
}
System.out.println("testMap1 avg time is :" + (totalTime / outSize));
// 省略其他方法,代碼跟上面一致
}
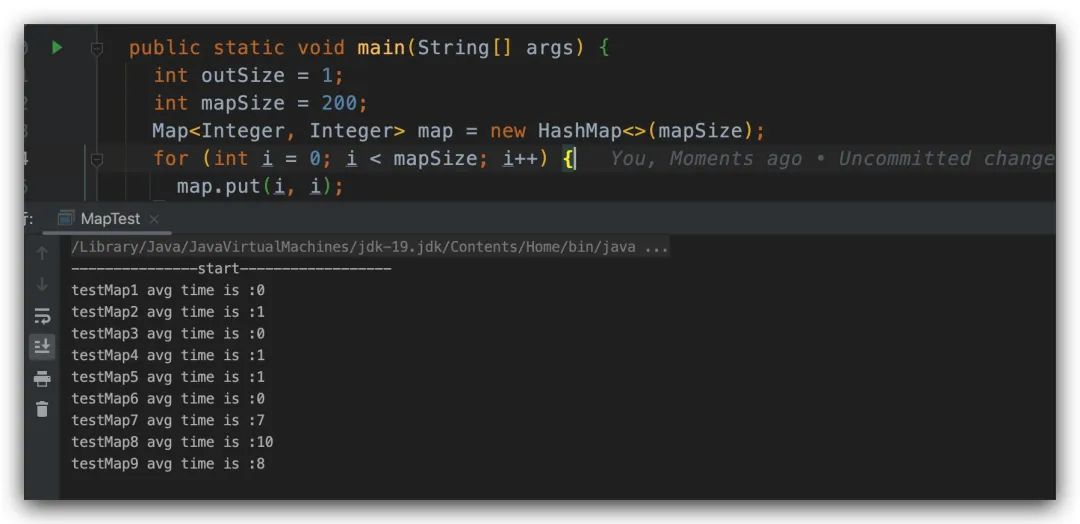
為了避免一些干擾,這里通過外層的 for 來(lái)進(jìn)行多次計(jì)算,然后求平均值,當(dāng)我們的參數(shù)分別是 outSize = 1,mapSize = 200 的時(shí)候,測(cè)試的結(jié)果如下
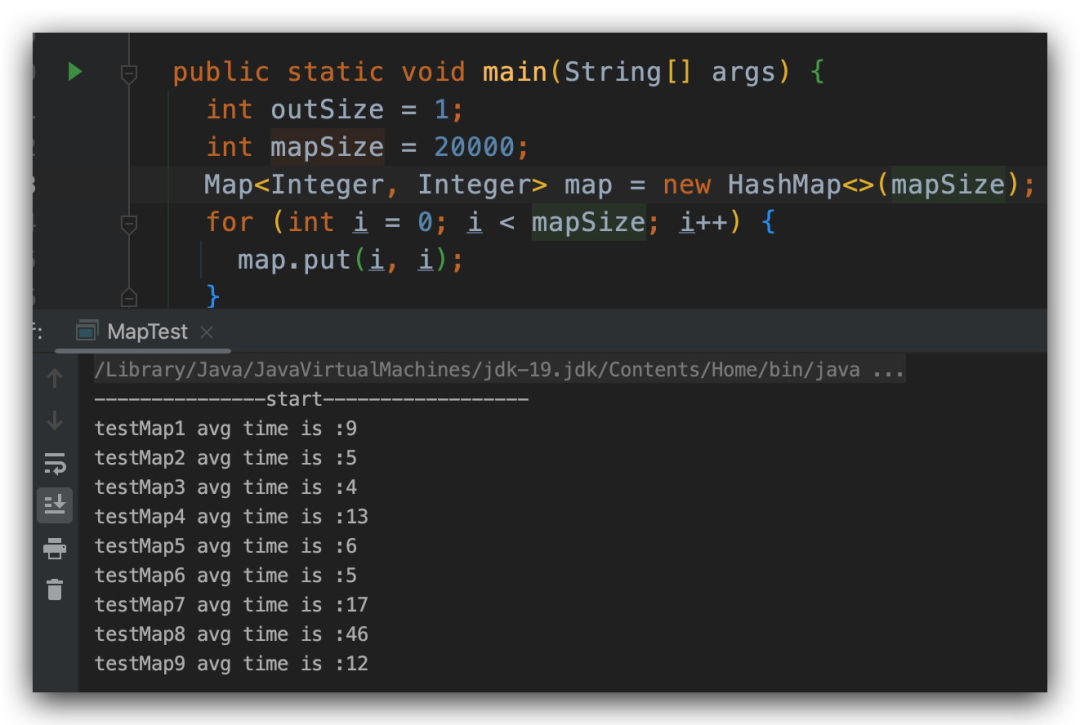
當(dāng)隨著我們?cè)龃?mapSize 的時(shí)候,我們會(huì)發(fā)現(xiàn),后面幾個(gè)方法的性能是逐漸上升的。
總結(jié)
從上面的例子來(lái)看,當(dāng)我們的集合數(shù)量很少的時(shí)候,基本上普通的遍歷就可以搞定,不需要使用 JDK 8 的高級(jí) API 來(lái)進(jìn)行遍歷,當(dāng)我們的集合數(shù)量較大的時(shí)候,就可以考慮采用 JDK 8 的 forEach 或者 Stream 來(lái)進(jìn)行遍歷,這樣的話效率更高。在普通的遍歷方法中 entrySet() 的方法要比使用 keySet() 的方法好。
 您現(xiàn)在所在的位置:首頁(yè) >關(guān)于奇酷 > 行業(yè)動(dòng)態(tài) > Java 中九種 Map 的遍歷方式
您現(xiàn)在所在的位置:首頁(yè) >關(guān)于奇酷 > 行業(yè)動(dòng)態(tài) > Java 中九種 Map 的遍歷方式